Microsoft Windows Friendly
inMemory+ has been specially designed for Microsoft Windows platforms: though it can also work for other platforms in a virtualized environment. This application relies on Microsoft’s latest technology stack. It harnesses the power of the Microsoft .NET platform and achieves the distributed architecture through Windows Communication Foundation (WCF) and makes use of Microsoft libraries to gain parallelism while processing data.
The core engine of inMemory+ is optimized for the Windows operating system and provides robust performance on all Windows O/S. Unlike inMemory+, the major in-memory database products available today are built for non-Windows platforms. inMemory+ delivers a robust and efficient in-memory database for an underserved community of users.
inMemory+ can easily be used with any other application or database. Its service-based connectivity makes inMemory+ a flexible plug-in with any platform, and the integration with other Windows based databases is uncomplicated. inMemory+ uses standard SQL syntax so it can easily be linked with other databases. The user interface is easy to use compared to other in-memory database products.
Easy to use User Interface
inMemory+ has an easy to use and accessible user interface (UI). It can be installed using a simple installer which has both standard and customized options. After installation, users can find the application in the Windows Control Panel and can easily repair and uninstall it from there. Administrators can manage all clusters without any complex or tedious tasks. Each cluster has a Master Node and Child Nodes. With inMemory+, the process of adding a Master Node to a server and adding other desired Slave Nodes is just a click away.
Based on default UI options, services are automatically initialized and started on a system start / restart. Thus, there is no human intervention needed if the application has been properly configured. The elegant UI makes cluster management easy and efficient. When any node goes up or down, the cluster manager updates the live nodes automatically. Therefore, there is no need to take the cluster down while installing a new node, it all happens seamlessly. inMemory+ solves the dilemma of complexity found in traditional in-memory products through its straightforward user interface. Users can import any table from an existing conventional database, synchronize the data perfectly, and load millions of records into memory in just a few seconds.
Users can perform analytical operations and querying on inMemory+ just like any other database. It supports standard ANSI SQL query syntax. Database and table creation is a single click operation. In the Query window, users can write a query, execute it, and see results with lightning speed.
Database Management
inMemory+ provides database management support through its user interface. Users can add or drop databases by right clicking on a database node. Databases can also be created and dropped through queries. It provides different types of databases, e.g., in-memory or file based. With in-memory types of databases, the data resides in memory until the inMemory+ server restarts. The inMemory+ database holds the data in memory and provides superior performance for data operations. Alternately, if users want to persist any critical information then they can use a file based database in which all data is saved on the disk. With this method, when a server restarts all user transactional data remains present in the database. Additionally, there is support for SQL server users to load their data from SQL server on the fly while creating a database. Users can provide SQL Server credentials like Server Name, user and password and connect to the SQL instance. After SQL connectivity has been established, users can select the desired database and its respective tables to load into inMemory+. Users can also load larger databases more efficiently by providing a batch size.


Schema Operations
Users can manipulate database schema through the UI or by using standard SQL queries. The following operations are supported by inMemory+.
- Add Table
- Edit Table
- Drop Table
- Add View
- Edit View
- Drop View
SQL Support
inMemory+ supports:
- SQL (DDL, DML)
- Joins: inner, outer, left, right
- Sub-selects
- Views
- Aggregate functions (Sum, Min, Max, Count, Avg)
- Mathematical functions
- String Functions
- Transaction


BLOB Support
inMemory+ Binary Large Objects (BLOB) support is designed for efficient storage of large objects. Users can use this data type to store information about images, audio files, video files and other oversized content.
Data Synchronizer
Data Synchronizer enables an organization to achieve accurate and consistent data across operational and transactional systems. With this data synchronization solution, an organization can quickly build business logic that handles the most complex data synchronization projects and reuse the same logic across data synchronization projects in batch, near-real-time, and real-time modes. The results are high performance, greater data accuracy and consistency, and a lower cost of ownership. Following are the benefits of using our data synchronization solution:
- Reduce the risk and minimize the common errors of data synchronization projects
- Lower IT costs of data synchronization by minimizing the time spent on integration and maintenance

- Improve business performance by ensuring up-to-date, higher quality consistent data across systems and people
- Improve data security, compliance, and visibility across the company, partners, and customers

Control Panel
Distributed applications are often hard to manage. There are a lot of services associated with this type of architecture leading to the management problems. Each time they are implemented there is a lot of work that goes into fixing the inevitable bugs and race conditions. Because of the difficulty implementing these kinds of services, applications usually skimp on them, which make them brittle in a dynamic changing environment and difficult to manage.
Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
Control Panel is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing deployment services. All of these types of services are used in some form or another by distributing applications. Control Panel facilitates such types of distributed applications and makes them free of the typical overhead necessitated by such complex types. It helps in making a cluster of nodes. You can easily add or drop nodes from a cluster with just a few clicks. It also allows users to install, uninstall, and edit services on any node through an easy-to-use interface.
Data Sharding
inMemory+ data sharding is a highly scalable approach for improving the throughput and overall performance of high transaction large database-centric business applications. Since the inception of the relational database, application engineers and architects have required ever-increasing performance and capacity, based on the simple observation that business databases generally grow in size over time. Adding to this trend is the proliferation of business data because of the maturation of the Internet economy, the Information Age, and the prevalence of high-volume electronic commerce. As any experienced database administrator or application developer knows all too well, it is axiomatic that as the size and transaction volume of the database tier incurs linear growth, response times tend to grow logarithmically.

The reasons for the performance and scalability challenges are inherent in the fundamental design of the database management systems themselves. Databases rely heavily on the three primary components of any computer:
- CPU
- Memory
- Disk
Each of these elements on a single server can only scale to a given point and past that point performance degrades. inMemory+ alleviates these issues with its shared-nothing architecture, and ability to scale elastically, allowing new machines to be introduced to a running database and become immediately available.
inMemory+ provides the following sharding techniques
Range Sharding: You can scale out by providing the range of values so each node will only contain the data residing under the defined range.
Count Sharding: In this technique, you state the number of records a slave can have.
Auto Sharding: In this sharding type you do not define any distribution criteria, all incoming data starts accumulating on the first available node. If data exceeds the configured memory limit, then it starts residing on the next available node.
Health Monitor
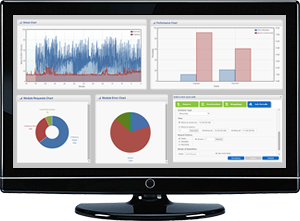
inMemory+ has the ability to perform real-time health monitoring. You can see the performance of all nodes present in a cluster.
inMemory+ has visualizations for CPU utilization and memory consumed by all nodes in a cluster. Real-time health monitoring helps users balance load on a cluster by showing what are the frequently used components. Users can also determine what modules are experiencing errors or exceptions in this same way.
Caching
inMemory+ has a powerful, easy-to-use caching mechanism that allows users to store objects in memory that otherwise would have required extensive server resources to create. Caching these types of resources can significantly improve the performance of an application. inMemory+ provides two types of caching, absolute and sliding. In absolute caching, data expires on a defined interval; while, in sliding caching, data expires if a call is not made for a specific interval since the last call.


Security
The inMemory+ security model supports users, roles, and privileges. Privileges can be granted/denied on a database role or for a specific user. Users can be assigned different roles and privileges. Users can be restricted to schema operations at the database or at the table level. Additionally, the security services of inMemory+ are secured for cloud environments.
Connectivity
inMemory+ allows users to connect with its engine in different ways. inMemory+ is installed as a service on a machine and exposes its interface on TCP and HTTP. This means that users from different operating systems and platforms can consume inMemory+ functionality easily. Additionally, code snippets to access inMemory+ services programmatically are available in its API help document.


Tracing
inMemory+ has efficient ways of tracing entire applications. The important events and performance parameters are logged, which helps administrators determine the health of applications. It contains detailed information such as transaction type, user actions, transaction data, log time, status, and machine information. Administrators can also use this information for audit trail purposes.
Error log
inMemory+ provides easy to read error and exception logs. Users can navigate to the error log screen and select the nodes and respective services to see errors coming from the application. In this way, administrators can have knowledge about the application's consistency and stability. inMemory+ provides the error details such as currently logged in user, error title, actual error message, stack trace, severity, log time, and the module name which generated the error.

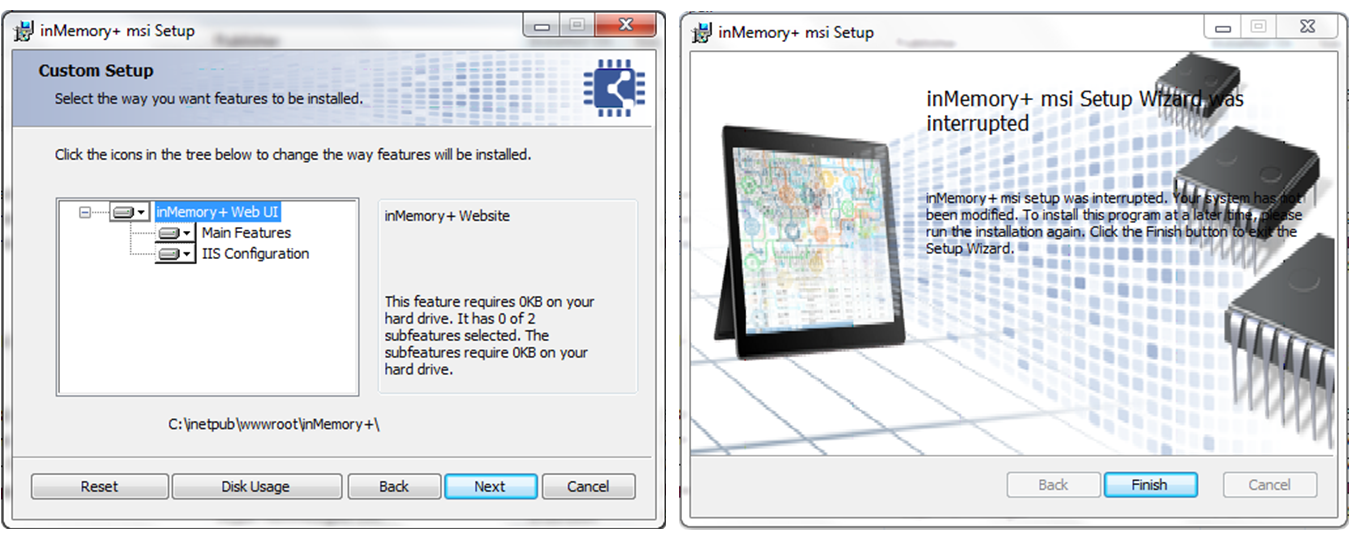
inMemory+ Installer
Typically, there are many challenges while installing and deploying distributed applications. The inMemory+ installer facilitates this task by providing a user-friendly interface for configurations and settings during the installation process. The inMemory+ installer automatically detects whether or not its prerequisites are already installed and in case of missing prerequisites, elegantly installs the needed files and frees the user from the headache of prerequisite installations.